
Hi, I’m Zifan (子凡), currently a Machine Learning Engineer at Adobe. I hold a Ph.D. in Computer Science from the University of Wisconsin–Madison, where my thesis focused on Data Validation and Selection for Modern Machine Learning. Prior to my Ph.D., I earned my B.S. in Computer Science from Shanghai Jiao Tong University.
My work lies at the intersection of data management and machine learning, where I explore ways to make data-centric processes more efficient and accurate. Currently, I’m working on exciting projects in entity linking and natural language to SQL (NL2SQL) systems, aiming to improve machine comprehension and interaction with structured data. Through my research and industry experience, I’m dedicated to advancing how we manage and utilize data to drive smarter, more robust ML models.
Thank you for visiting my website! Feel free to explore my work and reach out if you’d like to connect.
Warning
Problem: The current name of your GitHub Pages repository ("Solution: Please consider renaming the repository to "
http://".
However, if the current repository name is intended, you can ignore this message by removing "{% include widgets/debug_repo_name.html %}" in index.html.
Action required
Problem: The current root path of this site is "baseurl ("_config.yml.
Solution: Please set the
baseurl in _config.yml to "Education
-
 University of Wisconsin–MadisonPh.D. in Computer SciencesSep. 2018 - May. 2024
University of Wisconsin–MadisonPh.D. in Computer SciencesSep. 2018 - May. 2024 -
 Shanghai Jiao Tong UniversityB.S. in Computer ScienceSep. 2014 - Jun. 2018
Shanghai Jiao Tong UniversityB.S. in Computer ScienceSep. 2014 - Jun. 2018
Experience
-
 AdobeMachine Learning EngineerApr. 2024 - Current
AdobeMachine Learning EngineerApr. 2024 - Current
Selected Publications (view all )
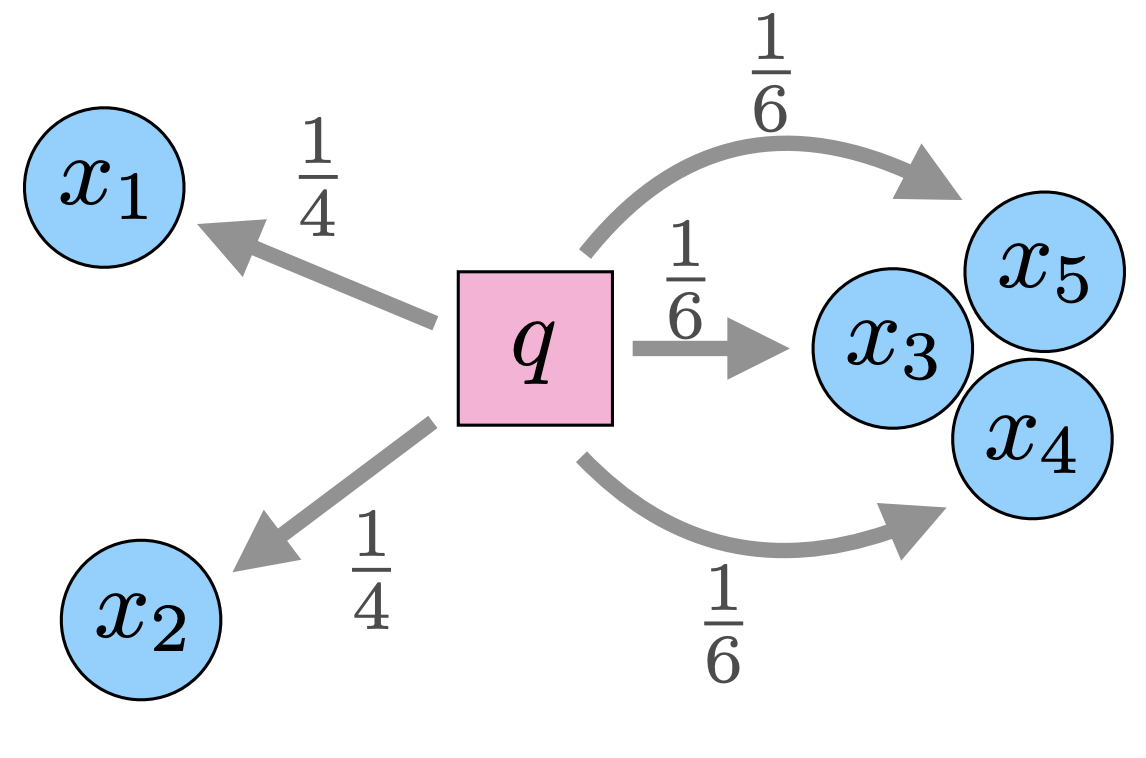
TSDS: Data Selection for Task-Specific Model Finetuning
Zifan Liu, Amin Karbasi, Theodoros Rekatsinas
Conference on Neural Information Processing Systems (NeurIPS) 2024
Finetuning foundation models for specific tasks is an emerging paradigm in modern machine learning. The efficacy of task-specific finetuning largely depends on the selection of appropriate training data. We present TSDS (Task-Specific Data Selection), a framework to select data for task-specific model finetuning, guided by a small but representative set of examples from the target task.
TSDS: Data Selection for Task-Specific Model Finetuning
Zifan Liu, Amin Karbasi, Theodoros Rekatsinas
Conference on Neural Information Processing Systems (NeurIPS) 2024
Finetuning foundation models for specific tasks is an emerging paradigm in modern machine learning. The efficacy of task-specific finetuning largely depends on the selection of appropriate training data. We present TSDS (Task-Specific Data Selection), a framework to select data for task-specific model finetuning, guided by a small but representative set of examples from the target task.
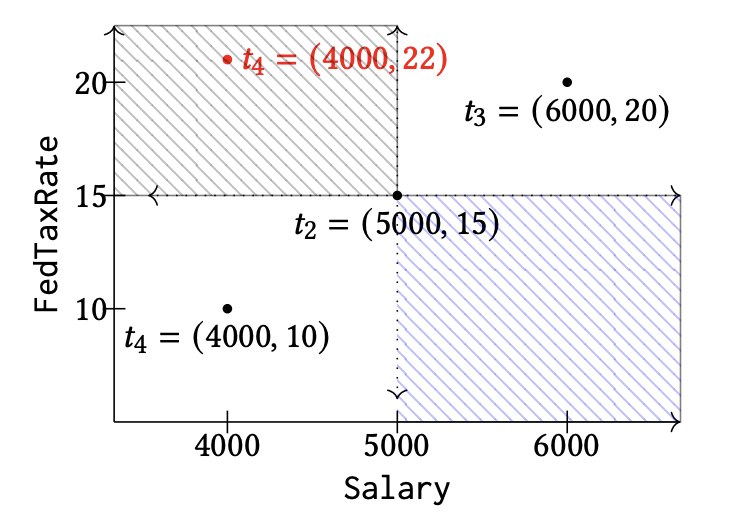
Rapidash: Efficient Detection of Constraint Violations
Zifan Liu, Shaleen Deep, Anna Fariha, Fotis Psallidas, Ashish Tiwari, Avrilia Floratou
International Conference on Very Large Databases (VLDB) 2024
Denial Constraint (DC) is a well-established formalism that captures a wide range of integrity constraints commonly encountered, including candidate keys, functional dependencies, and ordering constraints, among others. We establish a connection between orthogonal range search and DC violation detection. We then introduce Rapidash, a novel algorithm that demonstrates near-linear time and space complexity, representing a theoretical improvement over prior work.
Rapidash: Efficient Detection of Constraint Violations
Zifan Liu, Shaleen Deep, Anna Fariha, Fotis Psallidas, Ashish Tiwari, Avrilia Floratou
International Conference on Very Large Databases (VLDB) 2024
Denial Constraint (DC) is a well-established formalism that captures a wide range of integrity constraints commonly encountered, including candidate keys, functional dependencies, and ordering constraints, among others. We establish a connection between orthogonal range search and DC violation detection. We then introduce Rapidash, a novel algorithm that demonstrates near-linear time and space complexity, representing a theoretical improvement over prior work.

AutoSlicer: Scalable Automated Data Slicing for ML Model Analysis
Zifan Liu, Evan Rosen, Paul Suganthan G. C
NeurIPS Workshop on Challenges in Deploying and Monitoring Machine Learning Systems 2022
Automated slicing aims to identify subsets of evaluation data where a trained model performs anomalously. This is an important problem for machine learning pipelines in production since it plays a key role in model debugging and comparison, as well as the diagnosis of fairness issues. We present Autoslicer, a scalable system that searches for problematic slices through distributed metric computation and hypothesis testing.
AutoSlicer: Scalable Automated Data Slicing for ML Model Analysis
Zifan Liu, Evan Rosen, Paul Suganthan G. C
NeurIPS Workshop on Challenges in Deploying and Monitoring Machine Learning Systems 2022
Automated slicing aims to identify subsets of evaluation data where a trained model performs anomalously. This is an important problem for machine learning pipelines in production since it plays a key role in model debugging and comparison, as well as the diagnosis of fairness issues. We present Autoslicer, a scalable system that searches for problematic slices through distributed metric computation and hypothesis testing.
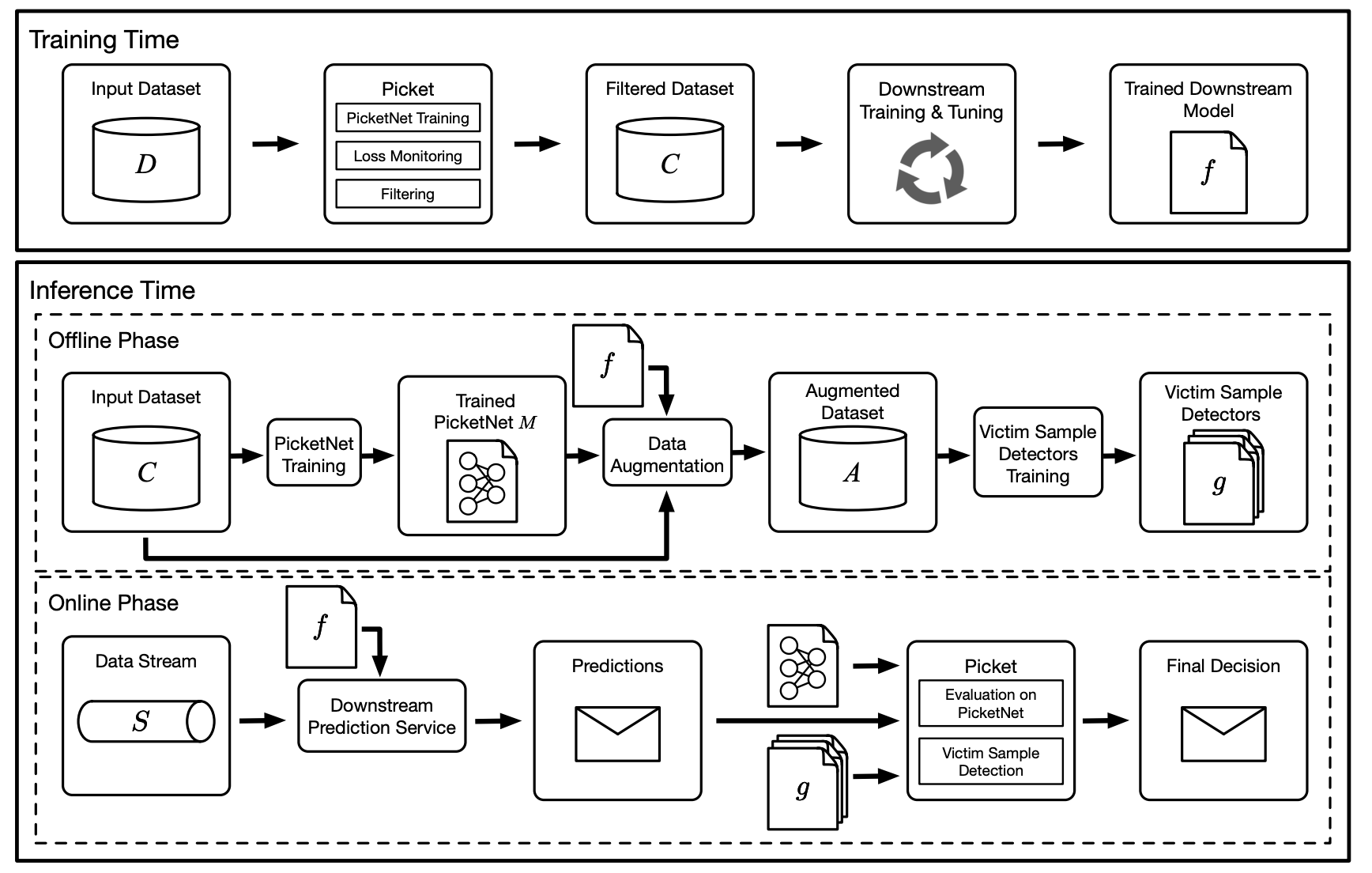
Picket: guarding against corrupted data in tabular data during learning and inference
Zifan Liu, Zhechun Zhou, Theodoros Rekatsinas
The VLDB Journal 2022
Data corruption is an impediment to modern machine learning deployments. Corrupted data can severely bias the learned model and can also lead to invalid inferences. We present, Picket, a simple framework to safeguard against data corruptions during both training and deployment of machine learning models over tabular data.
Picket: guarding against corrupted data in tabular data during learning and inference
Zifan Liu, Zhechun Zhou, Theodoros Rekatsinas
The VLDB Journal 2022
Data corruption is an impediment to modern machine learning deployments. Corrupted data can severely bias the learned model and can also lead to invalid inferences. We present, Picket, a simple framework to safeguard against data corruptions during both training and deployment of machine learning models over tabular data.
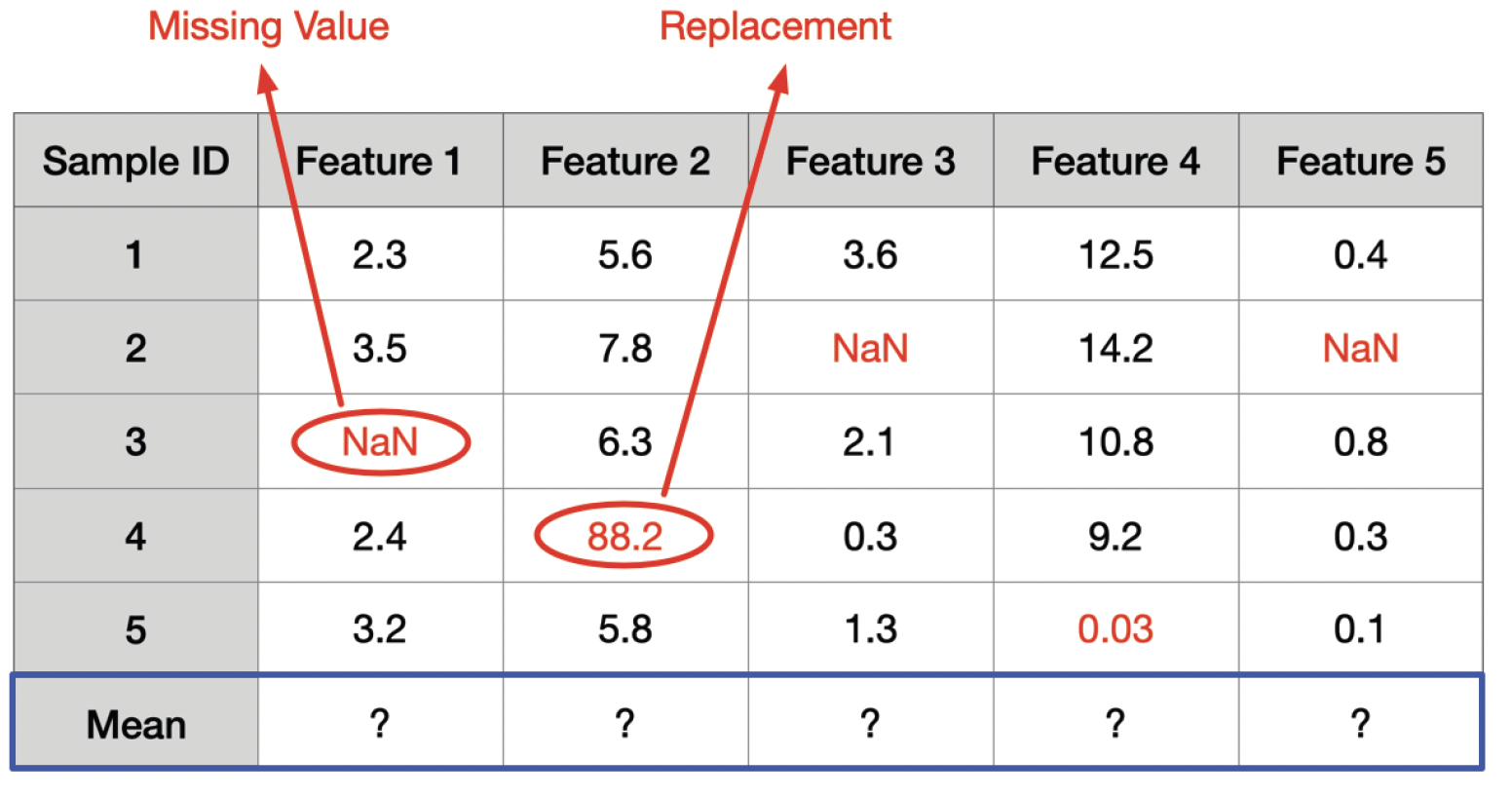
On Robust Mean Estimation under Coordinate-Level Corruption
Zifan Liu, Jongho Park, Theodoros Rekatsinas, Christos Tzamos
International Conference on Machine Learning (ICML) 2021
We study the problem of robust mean estimation and introduce a novel Hamming distance-based measure of distribution shift for coordinate-level corruptions. We show that this measure yields adversary models that capture more realistic corruptions than those used in prior works, and present an information-theoretic analysis of robust mean estimation in these settings.
On Robust Mean Estimation under Coordinate-Level Corruption
Zifan Liu, Jongho Park, Theodoros Rekatsinas, Christos Tzamos
International Conference on Machine Learning (ICML) 2021
We study the problem of robust mean estimation and introduce a novel Hamming distance-based measure of distribution shift for coordinate-level corruptions. We show that this measure yields adversary models that capture more realistic corruptions than those used in prior works, and present an information-theoretic analysis of robust mean estimation in these settings.